
GPT原理是什麼?它如何生成文字?
台灣師範大學圖書資訊學研究所特聘教授曾元顯回應,編造非事實的回應,是這類大型語言模型難以根除的現況。
因為,GPT系列的神經網路原理,其基礎模型是以自我監督的方式訓練出來的。他舉例,只要蒐集品質良好的大量語料,不必進行任何的人工標記與判斷、不需用到文法規則,輸入語料中的每一個文本,如下圖一之輸入:「人之初,性本⋯⋯」並將該句子的下個字當作輸出目標,如:「之初,性本善⋯⋯」然後要求GPT進行生成預測。
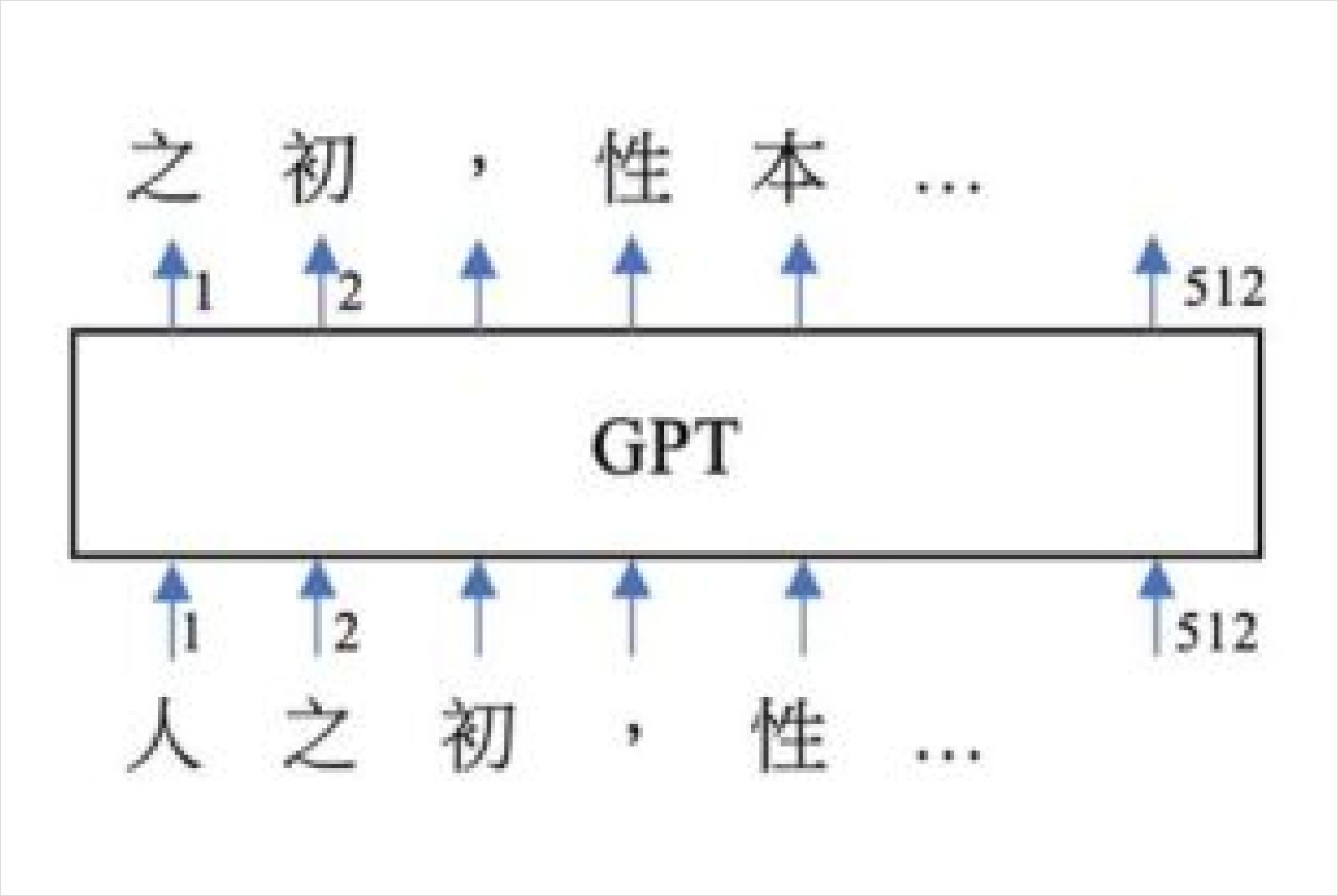 使用者輸入語料中的每一個文本,會用句子的下個字當作輸出目標,要求GPT預測。圖片來源:台灣科技媒體中心提供
使用者輸入語料中的每一個文本,會用句子的下個字當作輸出目標,要求GPT預測。圖片來源:台灣科技媒體中心提供
曾元顯提及,若相對應位置的字詞預測錯誤,就調整參數(以倒傳遞誤差的方式,按梯度下降法調整參數);究其內部,GPT這類模型只是上千億個小數點參數,在Transformer神經網路架構下進行運算,就可以得出人類語言的文字順序,完全沒有用到文法規則,沒有用到符號化的知識庫或是資料庫。
他觀察GPT的輸出,已經能理解語言,甚至具備語感,錯字比人類低,對於讀過的豐富主題,講得頭頭是道,非常神奇。但他仍提醒,GPT對文句「移花接木、再加潤飾」的能力超乎常人,但還是會生成錯誤的資訊;因此使用時,仍得謹慎。
同時,純粹的GPT模型裡面,沒有用到任何符號式的知識或是人類寫的離散式的規則;語言文字的知識規則,也已被GPT轉化成大量數值計算的連續性規則。這種連續性的知識表達方式,可以非常便捷、有效的內差(interpolate)出各種知識的變化,甚至於外插(extrapolate)擴增GPT從未看過的知識。這種知識表達方式以及其運算的能力,是這一波AI大幅成功的主因之一。
從模型的原理思考,曾元顯認為,GPT-3.5、GPT-4進一步用到人類導師導引以及強化學習的方式加以訓練,以抑制較差的輸出、獎勵較好的回應;但基本上,GPT-4仍有可能輸出無中生有、偏見、甚至錯誤的訊息。試想,使用者可以要求ChatGPT、GPT-4依照我們的指示,生成劇本;當這個劇情是天馬行空的想像,甚至要闡明什麼是偏見、謬誤、惡形惡狀時,ChatGPT可以生成這樣的劇情——也就是說,誤導、偏見的資訊並沒有從ChatGPT、GPT-4中刪除,只是被抑制,但仍然可能由某種提示被引導出來。
由上可知,編造文句是GPT的天性,此編造非事實的文句是我們不要的,但在某些場景下,使用者卻又需要。
針對AI生成文句的偵測研究,已有文獻微調了RoBERTa的模型並釋出程式,其識別GPT-2模型生成的網頁時可達95%的準確率;其他還有許多研究在協助偵測GPT生成的文字,協助辨別是否有錯用AI文字而有欺騙、造假、不公平的情事,以降低這波AI帶來的社會衝擊。
生成式AI普及,我們如何不被假訊息詐騙?
一但生成式AI越來越普及,使用者會不會更容易落入假訊息的詐騙陷阱?
中央大學資訊電機學院資訊工程學系教授蔡宗翰認為,GPT-4在生成文字時可能會編造非事實性的回答,這可能會對使用者造成誤導和負面影響。為解決這個問題,可以考慮引入更多的事實驗證機制和檢查機制,同時需要給予模型更加高品質的訓練資料。另外,語言模型的訓練資料可能存在一定的模型偏見,例如性別、種族、文化背景等方面的偏見。為了解決這個問題,需要更加細緻的調整和訓練模型,同時更加嚴格的審查和檢查模型的輸出結果。
總之,為提高GPT-4的解讀圖片和生成文字的能力,需進一步探索和研究相關的演算法和技術,也需要給予更多高品質的訓練資料和更加細緻的調整和訓練。蔡宗翰強調,台灣必須要有資源投入、深耕,以及研究訓練大型語言模型的技術,絕不能只是使用者,才不會在國際AI軍備競賽中落後;當遇到有心者利用GPT-4製造假訊息攻擊時,才有能力判別與解讀假訊息。
政治大學應用數學系副教授兼學務長蔡炎龍則說,要讓GPT-4產生有用、正確的東西,是使用者的責任;而文字生成模型它並不是有意識地提供不正確的資訊,所以刻意要造假消息的,用GPT-4不一定能更快速造出一個人要的假消息。他反思,這可能反而讓民眾更認為,堅持把關文字的媒體、出版社、或知名人物才是值得信賴的;相反地,照片、影片和聲音,反而不會再被大家認為是「有圖有真相」,社會要即早思考如何因應。
蔡炎龍想像,或許,之後有公信力的人或機構發佈的照片影音等,大家才可以相信;而讓可以錄影的相機、手機把認證訊息放入照片或影片中,證實真的是直接用這些機器拍下、沒有改造過,也才可能提高信任度。
你ChatGPT了嗎?使用須知8件事
不焦慮!我們不只有ChatGPT技巧,也為你整理AI思考包
AI趨勢:AI如何改變未來?
AI反思:AI會取代人類嗎?它如何為人類增強能力?
AI生活:為了與AI共處,我現在能做哪些準備?
參考資料與文獻
1. Rumelhart, D. E., & McClelland, J. L. (1986). Parallel Distributed Processing, Vol. 1: Foundations. Cambridge, MA: MIT Press.
2. Jawahar, G., Abdul-Mageed, M., & Lakshmanan, L. V. S. (2020). Automatic Detection of Machine Generated Text: A Critical Survey (arXiv:2011.01314). arXiv. https://doi.org/10.48550/arXiv.2011.01314
3. Solaiman, I., Brundage, M., Clark, J., Askell, A., Herbert-Voss, A., Wu, J., Radford, A., Krueger, G., Kim, J. W., Kreps, S., McCain, M., Newhouse, A., Blazakis, J., McGuffie, K., & Wang, J. (2019). Release Strategies and the Social Impacts of Language Models (arXiv:1908.09203). arXiv. https://doi.org/10.48550/arXiv.1908.09203
4. ZeroGPT:https://www.zerogpt.com/。
5. DetectGPT:https://detectgpt.ericmitchell.ai/。
6. OpenAI 自己做的 AI文字偵測器:https://openai.com/blog/new-ai-classifier-for-indicating-ai-written-text。
7. Data Portraits: Recording Foundation Model Training Data, https://arxiv.org/abs/2303.03919, 2023-03-06.









