
以下是簡立峰的分享:
大家已經關心生成式AI好一段時間了,今天我想從產業和技術的角度,來談當前的改變與挑戰。
ChatGPT流量從三月開始逐漸下滑,如果所有的科技革新都會帶起一次高峰,那這次可能已經過了;不過這三成的下跌,也可能是因為放暑假,暫時流失部分學生族群。
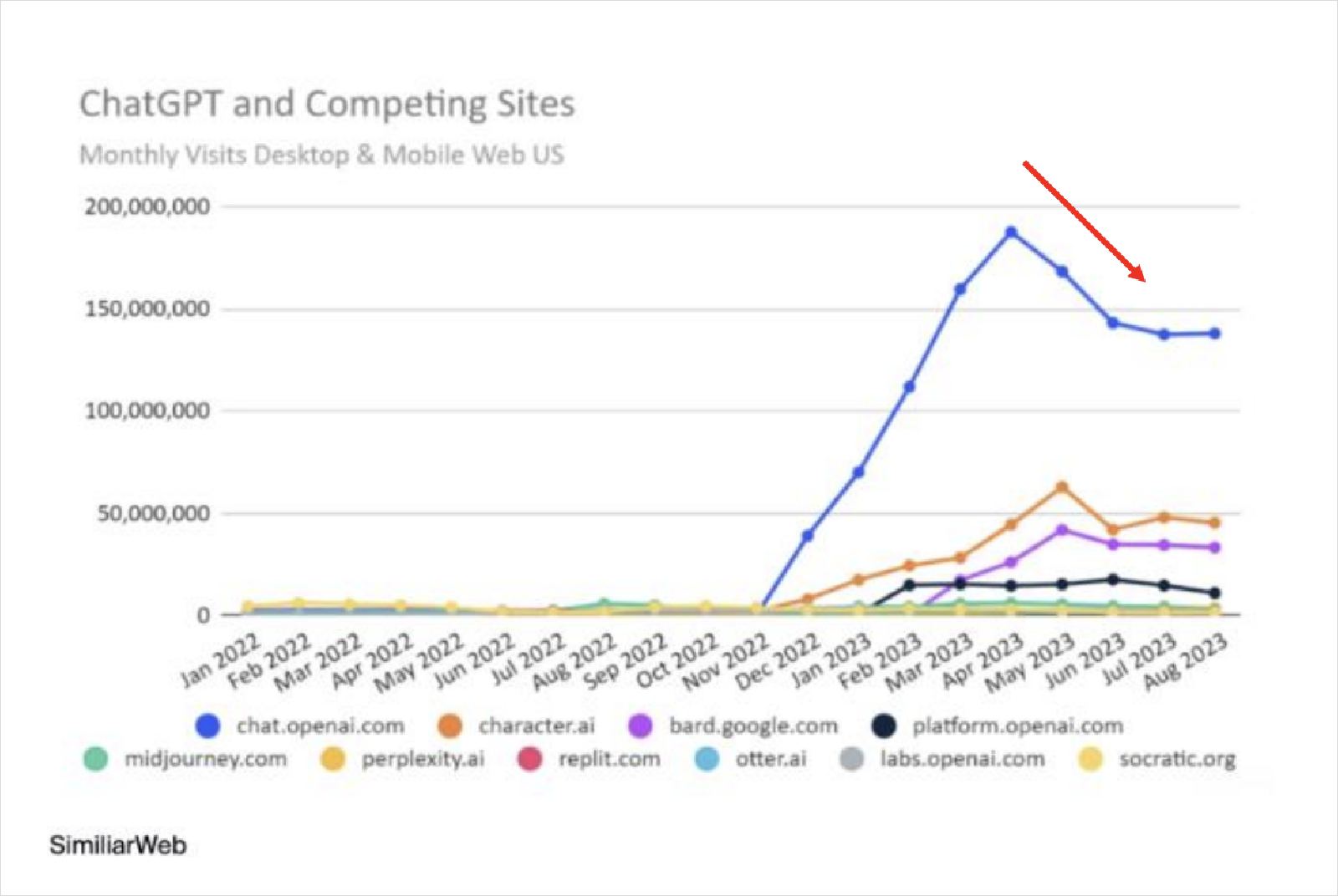 研究推測,ChatGPT使用量下降,可能是因暑假,而流失部分學生族群。圖片來源:截自簡立峰簡報
研究推測,ChatGPT使用量下降,可能是因暑假,而流失部分學生族群。圖片來源:截自簡立峰簡報
生成式AI的七大產業趨勢
生成式AI為產業帶來的第一個趨勢,就是AI生成內容能提高生產力。
觀察ChatGPT使用者的年齡分布,18到24歲佔約三成,40歲以下使用者佔近八成。我們應該觀察35到44歲這群白領工作者,如果他們的使用量高度成長、黏著性高,就會產生更多商業應用。
不過,如果白領族群使用需求沒有明顯成長,生成式AI帶來的生產力貢獻更多在學生的學習與作業上,而非產業或商業,就可能將成為未來的挑戰之一。
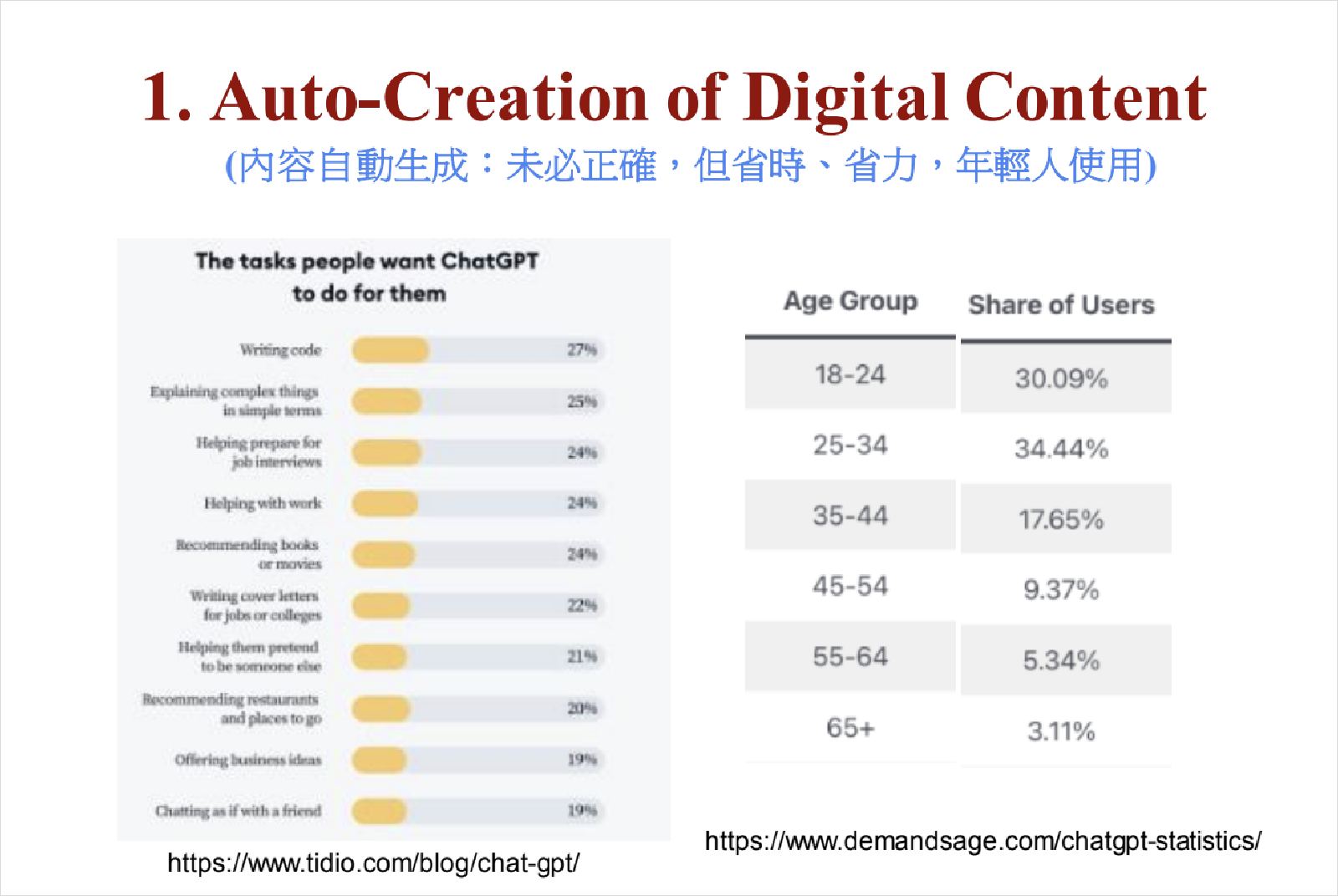 簡立峰認為,35到44歲工作者的ChatGPT使用量若提升,有助於可提高生產力。圖片來源:截自簡立峰簡報
簡立峰認為,35到44歲工作者的ChatGPT使用量若提升,有助於可提高生產力。圖片來源:截自簡立峰簡報
另外,ChatGPT使用者有兩億人,重度使用者約5,000萬人;觀察使用者分布可以發現,80%美國人並沒有使用ChatGPT,代表美國人並非ChatGPT使用者大宗,印度人相較用得更多。
趨勢二,對話式人機介面(Conversational Interface)愈來愈常見。Siri、Google各種服務開始串接大型語言模型後,未來發展拭目以待,人機對話介面可能逐漸成為軟體系統的標準配備。(延伸閱讀|台灣AI學校基金會秘書長侯宜秀:別焦慮,先建立「以人為本」人機協作生態系)
趨勢三,機器學習平民化(Machine Learning as a Service),這也是ChatGPT風潮帶來的一項重要改變。
機器學習的可及性提高,讓企業開始學「養小鬼」——訓練自己的小型語言模型(Smaller LLM),這在中國的說法是「煉丹」,而我們就是道士。因為在還沒完成之前,不會有人知道結果是什麼,成效有待觀察。
 簡立峰指出,ChatGPT讓生成式AI更「親民」,機器學習的可及性逐漸提高。圖片來源:台灣人工智慧學校
簡立峰指出,ChatGPT讓生成式AI更「親民」,機器學習的可及性逐漸提高。圖片來源:台灣人工智慧學校
趨勢四,學習下指令(prompts),人人都是工程師。現在我們透過問問題,就能解決問題。這是一種新的學習挑戰,下指令就如同在下咒語,某種程度上必須依靠個人領悟的程度。
趨勢五,勞動生產力提高。AI雖然帶來許多威脅與挑戰,不過在面臨少子化危機的台灣,如何維持勞動生產力是相當關鍵的問題,我想AI能發揮更多的是正面影響。
趨勢六,這麼多人都在買鏟子,那誰挖到了礦?我花了一個月的時間追答案,看起來,目前還沒有人賺到錢。
這使我想起2000年左右,Google找到廣告模式、Amazon有電商收入,成功從網路泡沫危機中存活下來,並成為贏家。現在大家都說大型語言模型很棒、生成式AI對工作有所幫助,但是目前尚無明確商業模式支撐OpenAI的營運成本。
使用者不願付錢,生成式AI可能將面對暫時性泡沫破裂危機,如何找到獲利方式並商業化,將是重要挑戰。
趨勢七,天下沒有白吃的午餐,AI有其代價。我們享受AI帶來的好處後,還得仔細檢視伴隨而來的資安、隱私、監管等問題。(延伸閱讀|組織如何導入ChatGPT?中研院:從做FAQ等「高影響、低複雜」任務開始)
大型語言模型的四大技術挑戰
從技術來看,第一項挑戰就是大型語言模型有其限制。模型透過情境學習並做出預測,數學、推理與規劃能力偏弱,即時回答的表現也不夠好。
另外,大型語言模型與搜尋引擎不同,在全世界任何一個角落問ChatGPT同一個問題,都會得到相同的答案,這將會形成嚴重的語言落差。
相反地,如果在台灣打開Google搜尋NTU,會出現台大;如果在新加坡,就會出現南洋理工大學。搜尋引擎透過每個使用者的行為與點擊紀錄,會出現差異;但大型語言模型尚未完全做到個人化機制,無法從使用過程創造差異化。
挑戰二,英文恐主宰生成式AI的內容。
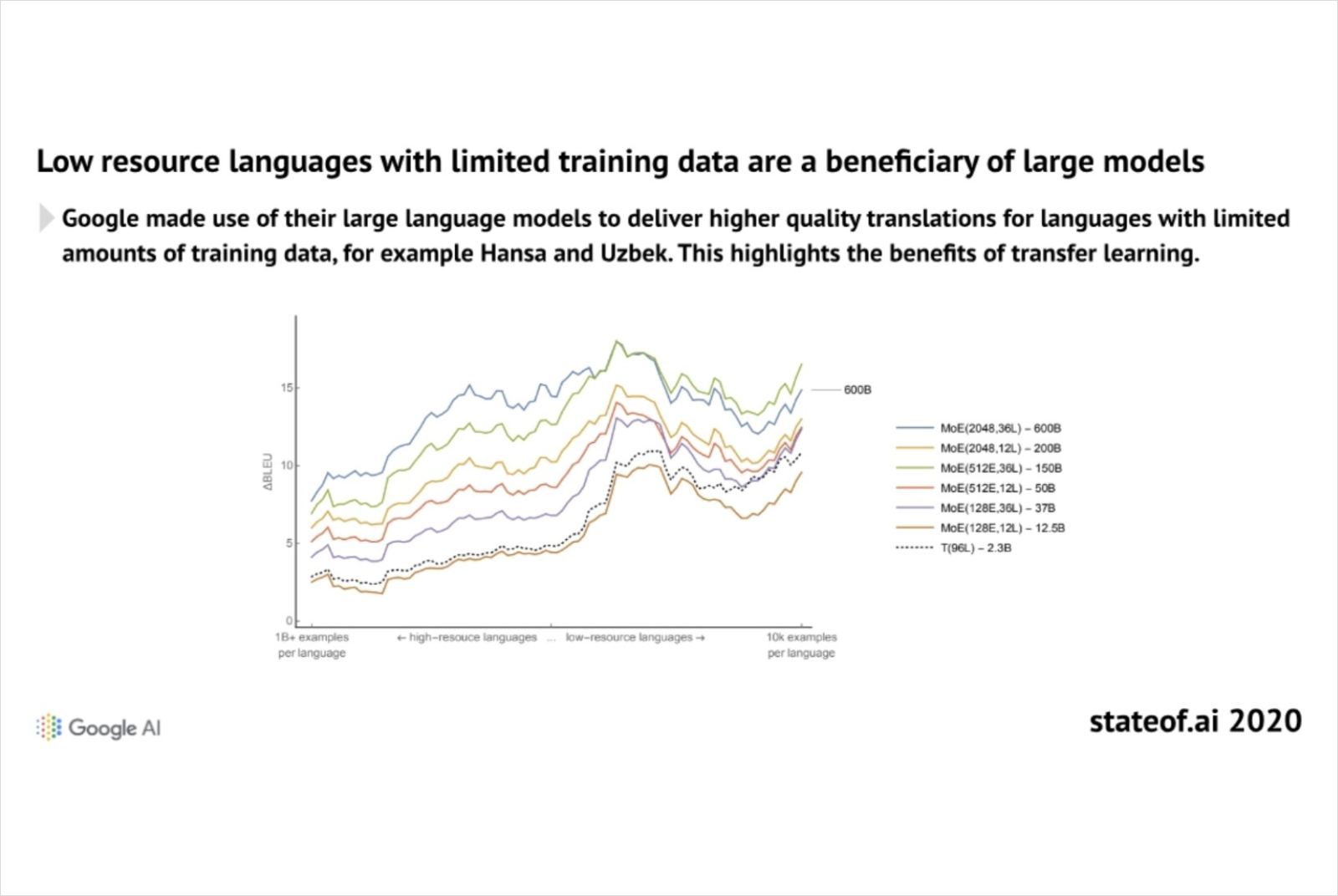 簡立峰引用Google AI資料指出,現有的資料庫多是英文,導致其他語言及文化更易遭到忽略。圖片來源:截自State of AI Report 2020
簡立峰引用Google AI資料指出,現有的資料庫多是英文,導致其他語言及文化更易遭到忽略。圖片來源:截自State of AI Report 2020
ChatGPT的原則是token-based(以詞元/分詞為基礎)而非langauge-based(以語言為基礎),它把每一種語言都視為token(詞元、分詞),目前可見的網路資料僅5%是中文,英文內容將主宰AI模型。若有人問他早餐吃什麼,它可能都會回答「漢堡」;或許你覺得這沒有太大問題,但其他語言的食物選項就會逐漸被忽略。
此外,今天所有的伺服器、電腦與GPU設計,原先都不是設計來為大型語言模型所用;如果每個企業都在訓練自己的模型,算力成本相當龐大,地球資源可能會不太夠用。
挑戰三,可使用訓練資料即將用盡。
OpenAI已經使用了五成網路資料(Internet data)作為訓練之用,還沒使用資料成長不會那麼快,品質好的資料也已所剩不多。
接下來,它很難依靠增加訓練資料來使AI變得更好,可能得改從微調(fine-tuning)等方式下手,這也是目前的瓶頸之一。
挑戰四,過去科學家出了好多考題去考AI,但過去幾十年題目都用完了,AI學生都考得太好,老師要重新出題目了。可是目前還沒有出題方向,沒有人知道該往哪個方向出題。
從這張圖表能發現,語音辨識能力從1990年起就進步,語言能力則在2016以後橫空出世,像是火箭一樣升上來。
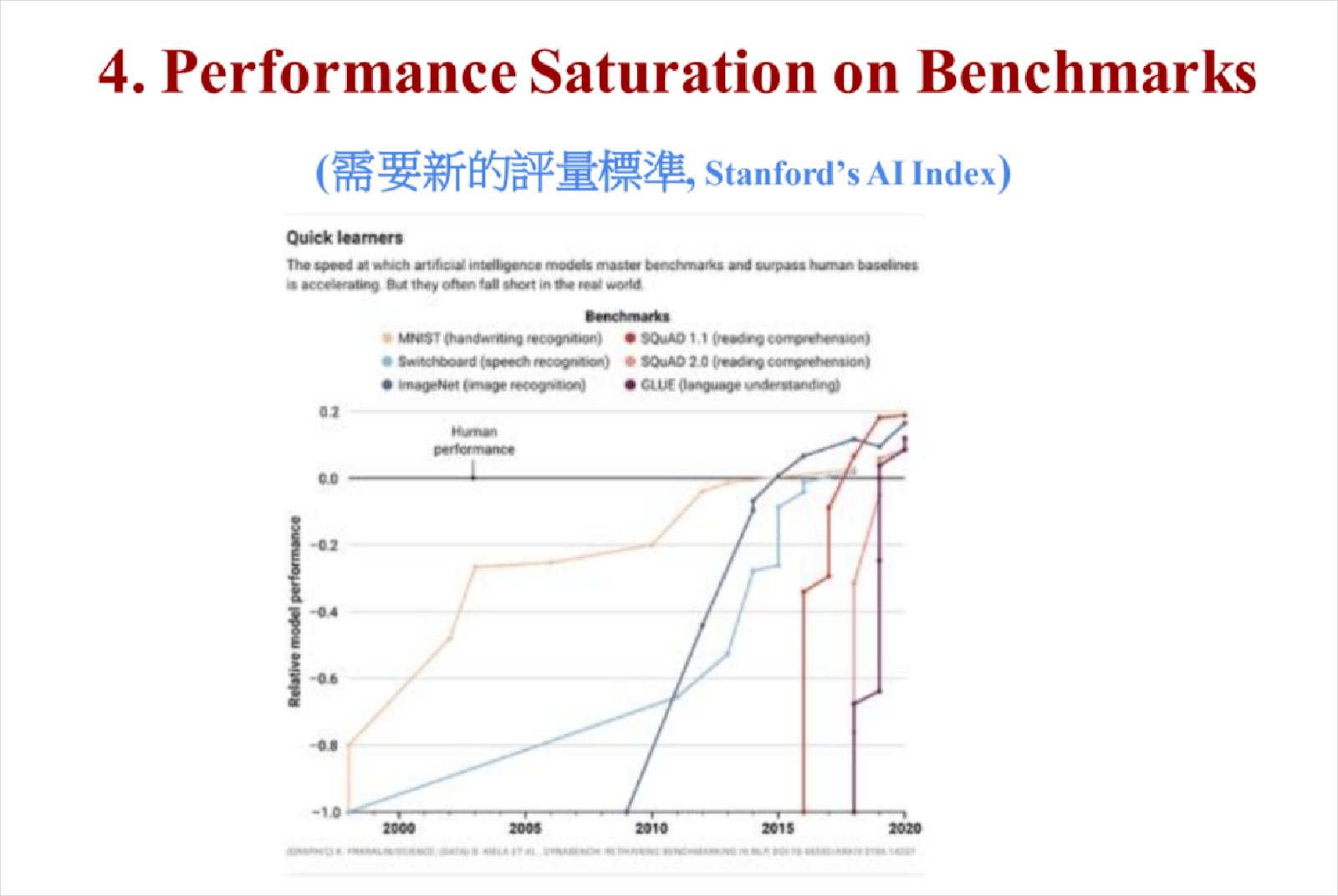 2016年起,AI的語言能力(紫線處)以驚人速度竄起。圖片來源:截自簡立峰簡報
2016年起,AI的語言能力(紫線處)以驚人速度竄起。圖片來源:截自簡立峰簡報
未來,AI發展推理能力的學習曲線,可能像語言能力一樣快速突破嗎?AI理解現實世界的能力突破有多快?如果AI跑得很快,那我們今天討論的所有社會風險,可能都被低估了。(延伸閱讀|簡立峰:算力即是霸權,OPEN才有AI)









